Pipelines
Pipelines leverage your prompts across any data query within HumanFirst Studio. This empowers use-cases requiring data transformation, generation or extraction at scale.
Creating a pipeline#
Assigned prompt#
A pipeline must have an assigned prompt to run. The input data of the pipeline will be run in isolation against the prompt.
Input data query#
By default, pipelines will run against your randomized unlabeled data. You can configure your pipeline to only use the data of any search query. This lets you leverage all the power of HumanFirst to process exactly the data you need.
Pipeline input data queries are similar to any other queries you would do on your data in HumanFirst, with the exception that pipelines are not able to leverage the stash and consequently the similarity to stash feature.
Limiting processed data#
By default, pipelines will run against the first 1000 items of their input data. This can be set to any limit, including the "unlimited" setting, which will run the pipeline on all its input data.
Pipeline caching#
Pipeline output is cached by prompt and utterance pair. As long as you do not modify the pipelines' prompt or its settings, it will only run once for any given utterance. This allows you to progressively increase the amount of data that gets processed without ever processing the same utterance twice.
Consulting pipeline output data#
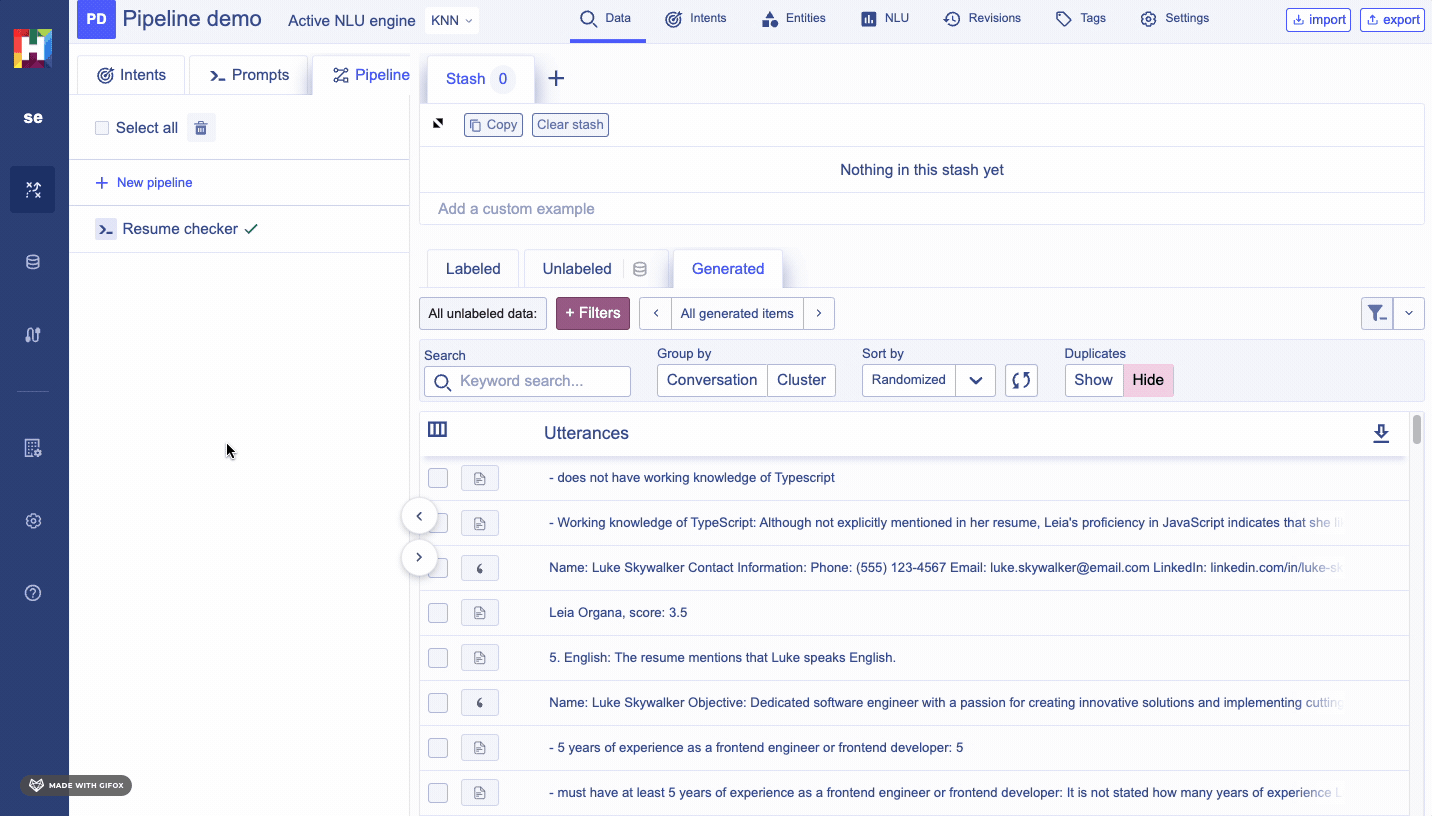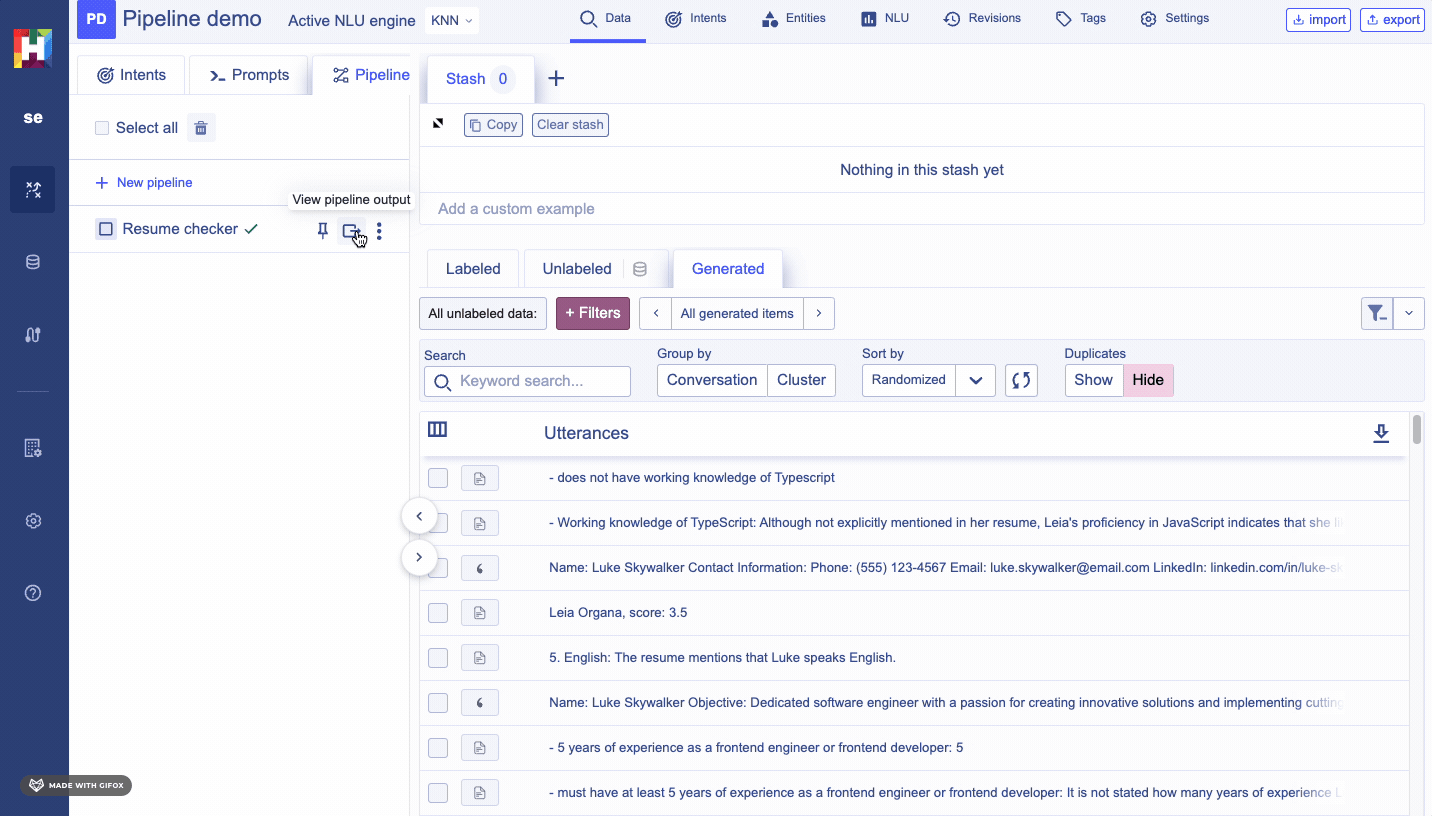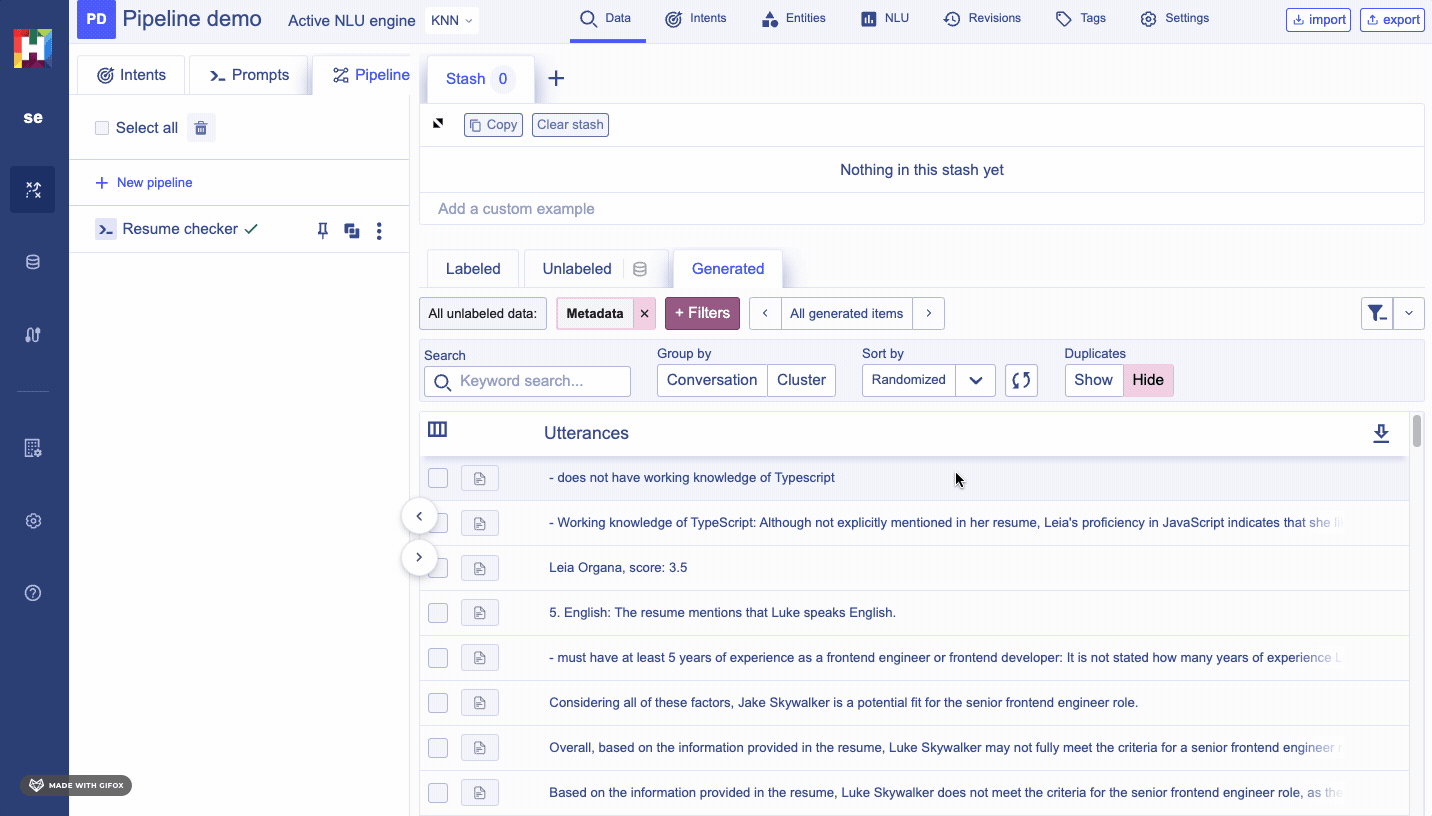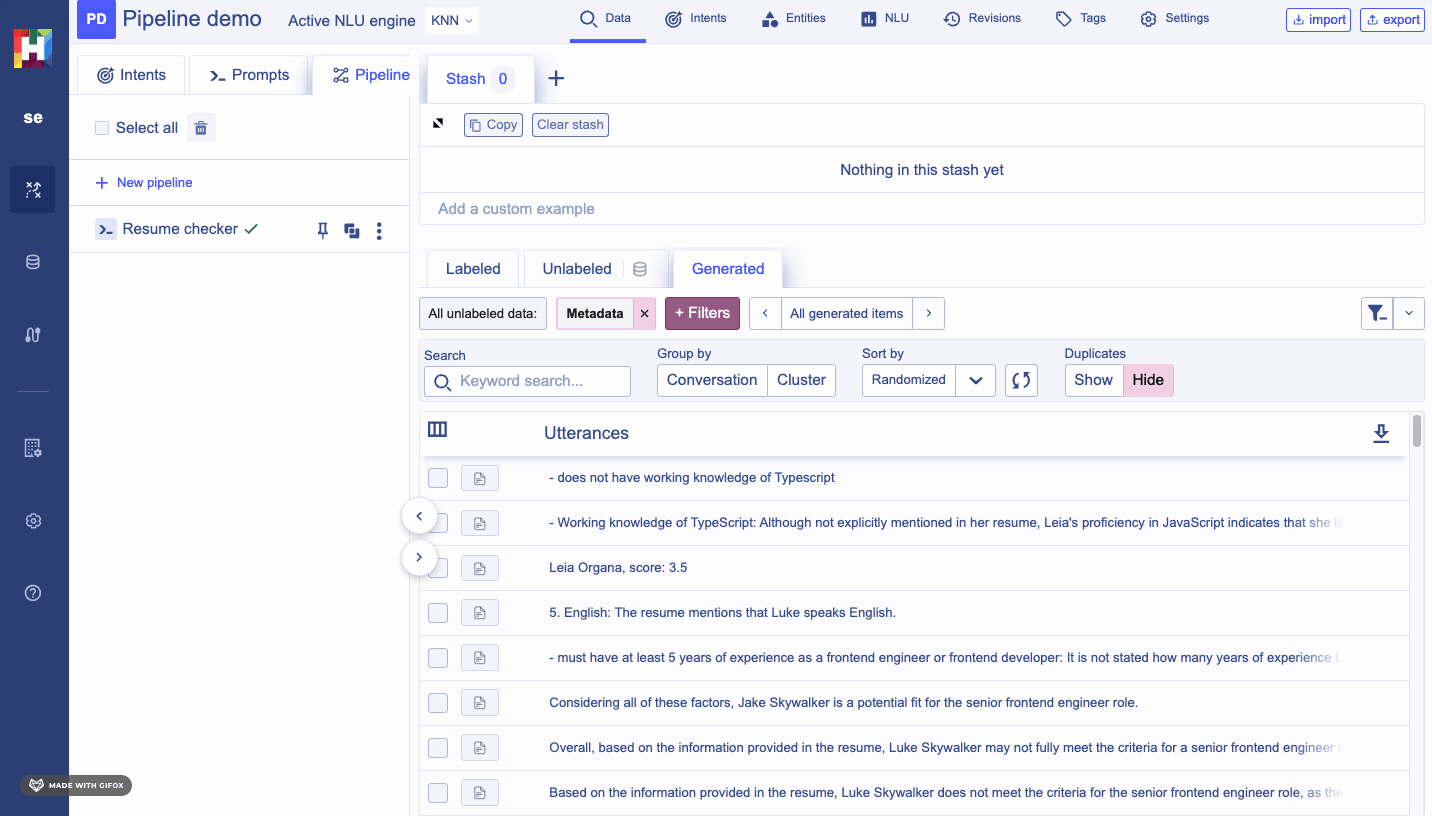
You can consult the latests output of a pipeline by filtering your generated data by the pipelineId, or by clicking on the view output button of your pipeline.
 ;
;
Pipeline data lifecycle#
Pipelines output is bound to the pipeline that created it. If that pipeline is deleted, the data is deleted as well. If the pipeline is re-run against a different input set, the previous output is lost.