Hierarchical Intents
HumanFirst supports and encourages the use of hierarchical intents. There are many advantages to having a hierarchical taxonomy:
Visualization#
Flat lists of intents can become very cumbersome and difficult to visualize. Having your intents organized hierarchically allows your models to scale by keeping topics organized and easily visualized.
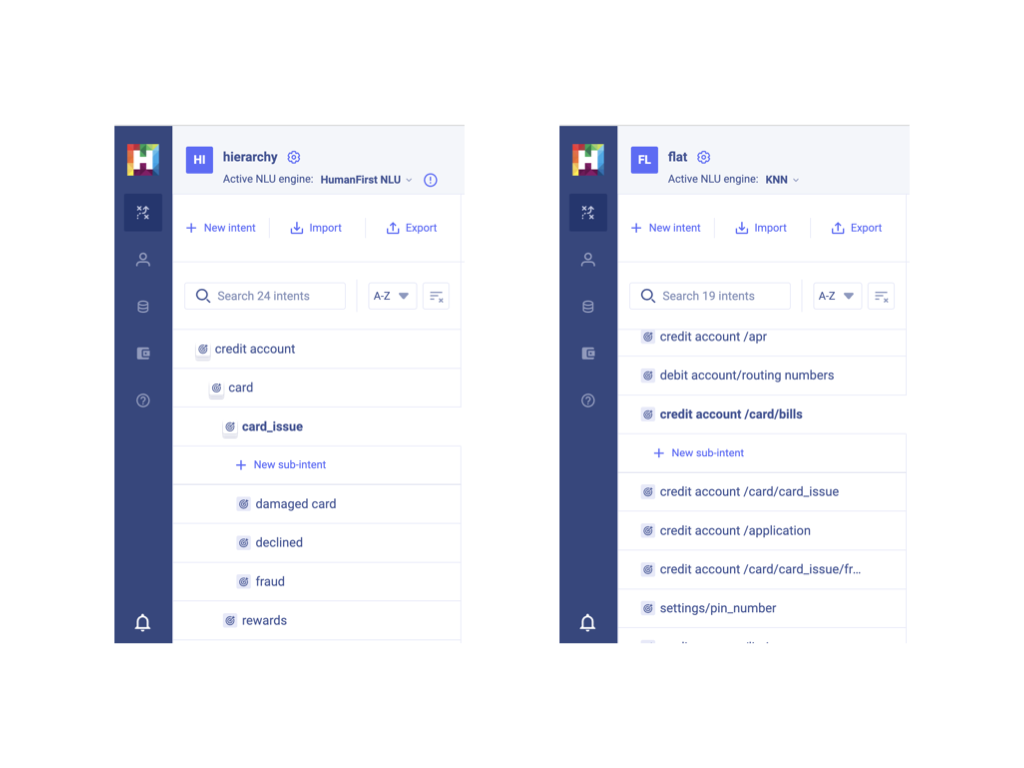
Classification at each level of granularity#
Some utterances can be very broad and difficult to classify correctly. Often, it will be difficult to classify such vague utterances, but having intents organized hierarchically helps alleviate the problem.
Let’s take a simple example where we have two utterances:
“I have a billing question”“I want to know when my bills are due”
The first utterance is very broad and could be easily misclassified. This is one way hierarchical intents can help:
The hierarchical relationship makes it clearer that the deeper and intent is, the more specialized/specific it's training data becomes. Conversely, the higher-level an intent is, the broader it's training examples should be.
Having intents organized this way also allows teams to have disambiguation type intents.
Taking the above example, the model could interpret: "I have a billing question" = We understand you have a billing question, can you pick one of these 5 options?
Exploration benefits#
Exploring by similarity using top-level intents will expose utterances that match to the top-level intent but have low confidence in matching to sub-intents, hence exposing potentially new sub-intents to be added or phrases that are under-represented in your sub-intents’ training data.
Training options#
There are two options for organising your data with parent intents.
1) Keep all training data in a child level.#
If you are intending to export your model to a target NLU not supporting hierachical intents, or if you are unsure which to choose this is the recommended default.
Where necessary create a general child with any remaining cases not covered by other children, i.e
- billing_issues (0 phrases)
- general_billing_issues (23 phrases)
- charged_twice (9 phrases)
- did_not_renew (11 phrases)
In this case the parent intent is only trained with the data contained within children
2) Have general cases as training under the parent intent#
- billing_issues (23 phrases)
- charged_twice (9 phrases)
- did_not_renew (11 phrases)
In this case the parent intent is trained with the training at the parent level and contained within the children.
Logic determining when a parent intent will be returned in a classification#
When using the test panel in studio, within evaluation results, or when using the predict or batch predict APIs it is possible then to have a parent intent returned as the best classification rather than a child of the parent. This occurs when
If the children’s margin ratio is above 0.80 then the parent will be returned instead. (This can occur whether you have training at the parent intent or not so in both training style 1 and 2 above)
If the parent score itself is higher than the sum of the child scores, then the parent is returned. (This is only likely to occur if you are using training style 2 and have training at the parent level as well as the child level)
If you do not wish the tool to return the parent in these cases, and to interpret the tree of child results yourself this behaviour can be disabled perworkspace. Currently this is done by the backend - please contact your account representative if you'd like to disable this feature.
Turning on or off parent matching#
Parent intent matching can be turned on or off at the workspace level per NLU engine that supports it.
Under "Workspace Settings", under NLU engines, select the NLU engine you wish to change options on (Normally HumanFirst NLU) There is a small crayon edit settings button on hover to the right of the name.
"Include parent intents in predictions" has three settings:
- Yes - match parents in above situations
- No - never match parents
- Default - depends on NLU engine - for HumanFirst NLU engine this is Yes for most external engines it will be No
If the setting is turned off it will no longer happen in any part of the system. So this will stop:
- parent level exploration of data
- parents being returned through predict or batch predict engines
- parents appearing in K-Fold evaluation results
- parents appearing in disambiguation.
Naming convention considerations#
If you are planning to export your data to a target NLU not supporting hierarchical intents the studio will flatten on export the representation for you using any supplied delimiter and omit the empty parents.
Establishing your prefered naming convention for labels will make this process more straight forward for you.
Consider:
- what limitations of characters will the target system require?
- Must it be an URL compatible name?
- Are spaces allowed?
- is there a limit on total characters
- reserve carefully your chosen delimiter
- avoid reincluding the parent name in the child name
- what uniqueness constraints are there at each level
A suggestion that has high resability and produces names easily readable in an URL is
- intent name labels all lower case, no punctuation, words separated by underscores
- delimiter =
- - try and limit labels to 2-3 key words for a phrase most representing the sentance
- typically avoid reincluding the parent name in the child name (the final name will already include the parent)
- however for general classes ensure the child will still be fully unique so avoid "general" and aim for "general_billing_issues"
So for the example above parent intent around "Billing Issues", with children about "general issues", "being charged twice" and "didn't renew" this might produce output names like
billing_issues-general_billing_issuesbilling_issues-charged_twicebilling_issues-did_not_renew