Data Pipeline
Overview#
Our data pipeline powers most of Studio's features by controlling the scheduling, training and deployment of NLU models and artifacts, and exposing them via our APIs.
- Uploaded conversation and utterance data is mapped to an internal representation that keeps track of the source of each training example.
- Examples are projected to a latent space representation (capturing the semantics of each example) and are indexed using optimized spatial indexing techniques.
- Traditional full text indexing is also performed in parallel.
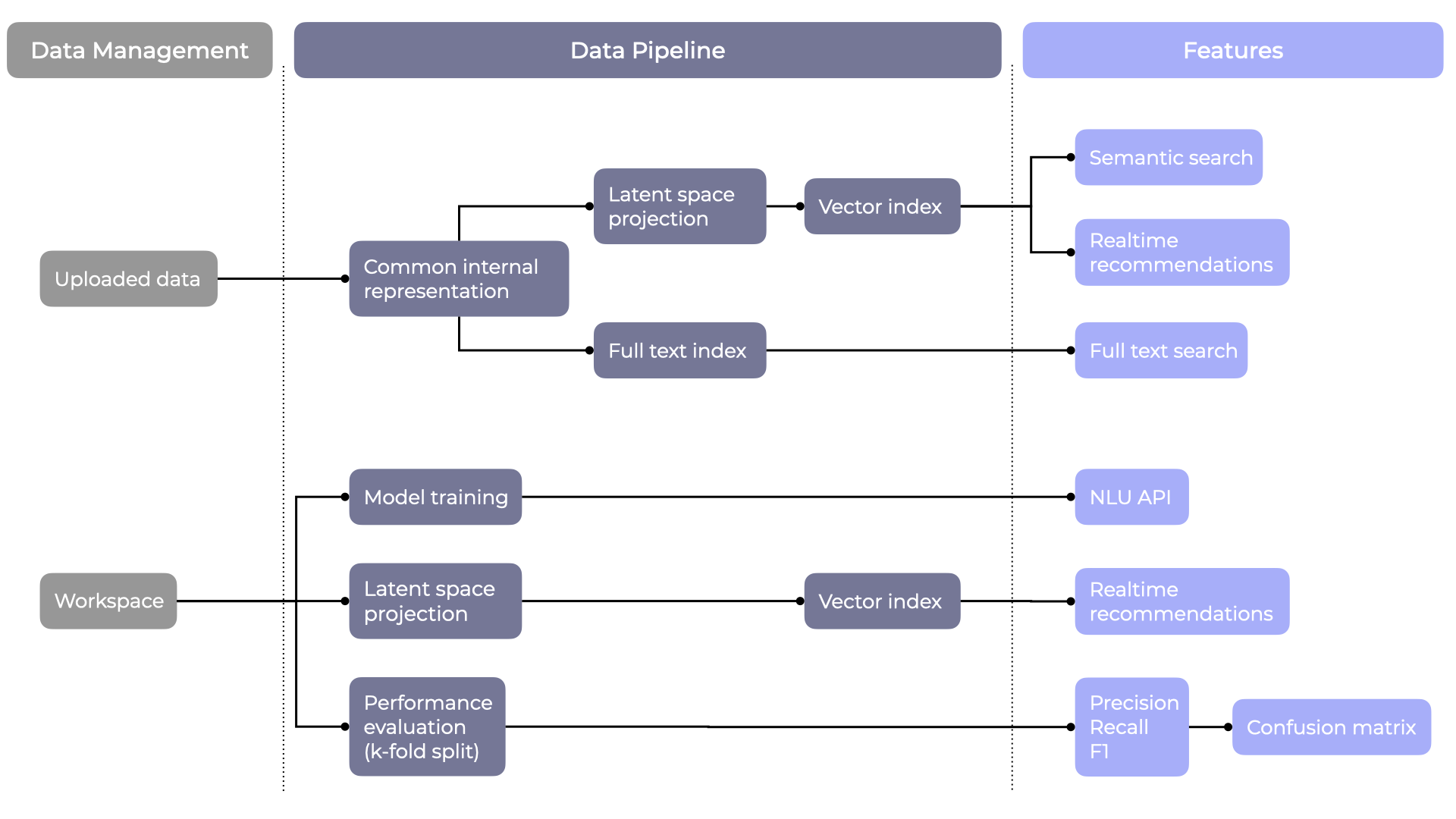
Our data pipeline manages and schedules jobs for any change related to the workspace, and continuously deploys updated models that are served throughout our clusters by feature-specific services.
info
This means that anything done through Studio can be accessed via APIs, and models are automatically kept up to date in order to give accurate results.