Anonymize Data
Cleansing unlabelled data for upload of personally idendifiable material#
🦸SuperPower Objectives :#
- Use Microsoft Presidio to replace examples of person names and telephone or account-a-like numbers in the dataset
- Create an unlabelled workspace from them
Example#
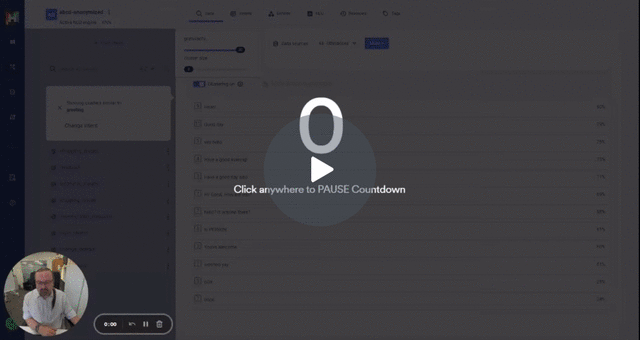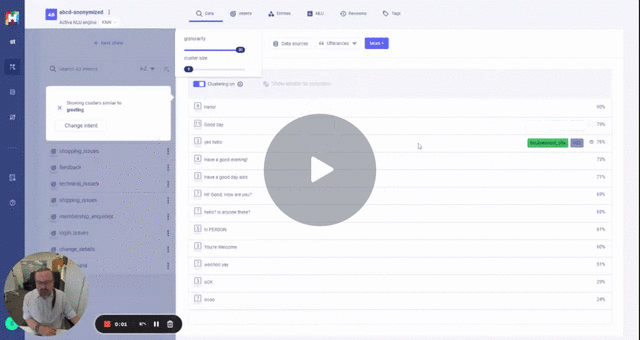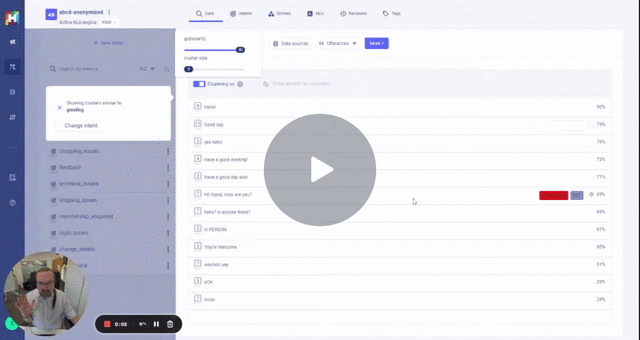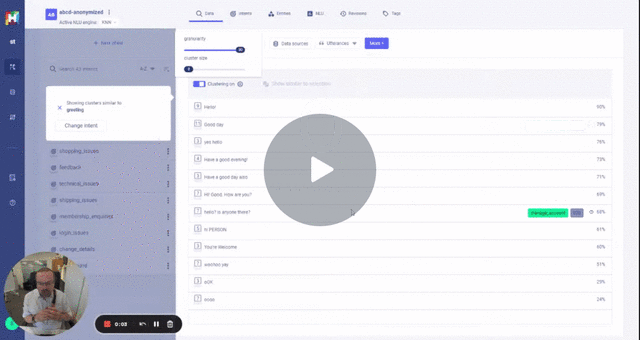
If you check ./data/abcd_unlabelled05.json you will see the anonymization of a sample of utterances.
Anonymization is expensive in CPU and Memory (utilises spacy large language model) running the script on the full set will take a while.
Microsoft Presidio is available under the MIT license.
Check out the uploading data exercise Load Data for how to upload your data.